A simple way to see how effective your storeroom is at providing the right part, at the right time, in the right quantity.
 Storerooms are a critical part of any maintenance and reliability program, but they are often overlooked. When a storeroom is operating at best in class levels, the right parts are available at the right time. The storeroom is only able to achieve this when it its into the maintenance department.
Storerooms are a critical part of any maintenance and reliability program, but they are often overlooked. When a storeroom is operating at best in class levels, the right parts are available at the right time. The storeroom is only able to achieve this when it its into the maintenance department.

 Performing a
Performing a 
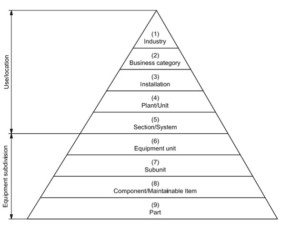
 In the petroleum, natural gas and petrochemical industries, great attention is being paid to safety, reliability, and maintainability of equipment. This is true in any industry and as such the learnings and
In the petroleum, natural gas and petrochemical industries, great attention is being paid to safety, reliability, and maintainability of equipment. This is true in any industry and as such the learnings and 
 Based on our understanding of the six failure patterns, we can see that there is a large probability of failure when the equipment is first installed and started up. One of the Englisch causes of this increase in probability is the fact that the equipment was not installed or maintained correctly. This may be due to the installer or maintainer not using or following procedures. Having procedures is the first step to reducing these failures, but the procedures must be written in a clear, easy to follow manner. When writing procedures, it is critical to ensure that there are no interpretations in the written instructions. How can this be accomplished?
Based on our understanding of the six failure patterns, we can see that there is a large probability of failure when the equipment is first installed and started up. One of the Englisch causes of this increase in probability is the fact that the equipment was not installed or maintained correctly. This may be due to the installer or maintainer not using or following procedures. Having procedures is the first step to reducing these failures, but the procedures must be written in a clear, easy to follow manner. When writing procedures, it is critical to ensure that there are no interpretations in the written instructions. How can this be accomplished?

 Why is that some organization seem to break the reactive cycle and others don’t? After all most organizations have a
Why is that some organization seem to break the reactive cycle and others don’t? After all most organizations have a 
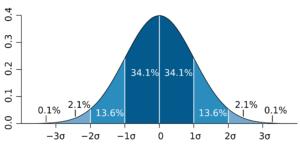
 Ever wonder how some of the worst industrial disasters occur? It is usually the result of multiple failures. Failure of the primary system and failure of the protective systems. Ensuring the protective system(s) are not in a failed state should be of utmost importance to any organization. But how often should we test the protective systems to ensure the required availability?
Ever wonder how some of the worst industrial disasters occur? It is usually the result of multiple failures. Failure of the primary system and failure of the protective systems. Ensuring the protective system(s) are not in a failed state should be of utmost importance to any organization. But how often should we test the protective systems to ensure the required availability?