
Entropy and maintenance are more related than you might think. What happens in maintenance and many operations can be explained with this simple thermodynamic concept. Entropy is a concept that represents chaos and degradation. It occurs naturally in any physical system and will naturally grow (i.e.: the system will become more chaotic) if we don’t do something to arrest its growth. Doing something requires the expenditure of energy, so energy is what counters entropy. Entropy and maintenance are seldom discussed together, we don’t speak of these thermodynamic terms and concepts in everyday language and conversation, but they are at work behind the scenes. For practical purposes, if we want something to remain orderly we need to put some form of energy (effort) into keeping it that way. If we don’t, then nature will steadily and relentlessly increase the state of chaos in which we exist. In maintenance that means moving from proactive (which requires energy) to reactive (which drains it away).
Reliable performance by our installed systems is what we want. We get that by designing systems to be reliable, operating them properly (i.e.: not overstressing them), and by maintaining them properly so the inherent reliability designed in, can be achieved.
Doing all of that requires an investment in design, training, maintainability, and maintenance program development. That effort is the energy we must put into any system to minimize entropy (chaos).
We get off to a good start by having a system that is capable of being stable – good design and preparation of our operating crews provide that. Then we must keep it stable because even the best design will degrade in capability over time, sometimes quickly, sometimes gradually, but always degrading. That natural degradation is how we realize the growth of entropy in our “built” world.
Design and engineering are the first things we need to invest in. Next are operations and consideration of entropy and maintenance.
“Operate and maintain” (O&M) is usually the longest phase of a physical asset’s “life cycle” by far. The time from concept development through design and construction can take a few years, but O&M can last for decades, especially in large industrial facilities. Long after the money (energy) is put into providing reliable design and making sure it can be operated well, we are still spending money (more energy) maintaining it. There are two things we maintain – the system itself and the capability of those operating and maintaining.
The latter has already been touched on in the 2nd part of this series. Initial training won’t be enough. It is well known and documented that knowledge, like physical assets, also degrades over time, especially if it isn’t used a lot. Considering that our knowledge is carried in electrical impulses in a vast neural network we call the “brain”, then that natural decay is yet another manifestation of entropy. We need to do something to counter it. We need to put energy into maintaining that knowledge, skill, and ability to operate and maintain. Again, training is what we invest in to do that. We are investing indirectly in our people and their ability to do their jobs well.
Maintenance of the asset itself is another form of energy we need to invest in, in two ways: proactive and repair. Within limits (note that we can overdo it here) the more of the right proactive work we do, the less repair work we will do. Proactive costs will rise, but repair costs (which are usually a multiple of proactive costs) will fall. Overall maintenance costs (total) will fall.

If you think of a pie with two slices – one proactive (green – low entropy) and one reactive (red – high entropy). With poor maintenance, the reactive slice (high chaos and entropy) will be much larger. With the right amount of proactive maintenance (energy) though, the reactive slice will be smaller but more – the overall size of the pie shrinks! This is all good news too because our overall costs will fall.
And more! The reduced downtime for maintenance also means less downtime for your operators so any overtime costs associated with catching up on production run quotas, etc. are reduced. Reduced downtime means more uptime – you get more productive output. If we define failure as any defect that takes the machinery outside of desired performance parameters, then we’d be catching problems before we see their negative consequences. Quality would improve, we’d have fewer leaks and emissions and equipment would run in the most efficient operating bands. Overall your unit costs of production will go down because you get more output and at a reduced cost of the inputs. What’s not to like about that?
There’s also another big economic effect that people often overlook. Your margins will also increase.
Maintenance costs have both variable and fixed components. Fixed costs are those you spend even when your facility is shut down. You don’t simply close the doors and abandon it, so that little bit you spend on preserving the equipment so it can be used again becomes part of your fixed costs. For instance, you may still pay to keep it lit, heated (to avoid freezing in winter), etc. This fixed cost is constant.
Variable costs increase and fall with production levels. The more you produce, the more use your assets get, and the more you need to spend maintaining them. As they run your assets consume lubricants, belts wear out, bearings fail, metal fatigues, etc. The line representing variable costs slopes upwards to the right as production levels rise from zero.
Revenue is earned as you produce, so the revenue line rises from zero when you are producing nothing, to 100% at the point where you achieve a 100% production level. Let’s assume that whatever you produce is always sold at a constant price. The revenue line won’t budge.
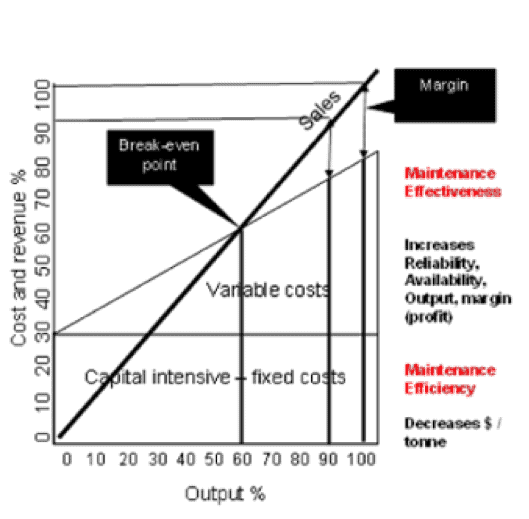
There is a breakeven point. At that point, the revenue line rises above the top of the sloped cost line. To the left of that point, you are losing money, to the right you are making money. The amount you make is referred to as “margin”. Ideally, the “margin” is as wide as possible.
Note that you make more margin at higher levels of production where the gap between revenue and costs is greater. If we can move the breakeven point to the left, then we can increase the margin and become profitable at even lower levels of production. The entire business is more sustainable.
Doing the right maintenance can impact on both fixed and variable costs. If we lower the fixed cost, then we lower the total cost and move the breakeven point to the left. If we can reduce our maintenance costs per unit of output by doing the right maintenance (remember that the right amount of proactive maintenance reduces the more expensive reactive maintenance), then we reduce the slope of the variable cost line. That also increases the margin.
So how do we achieve that?

Reliability is like the top of a three-legged stool. To support it we need engineering, operations, and maintenance. We want the maintenance leg of our stool model to be the right length – not too short, not too long. It must be tailored to fit the design and operating capability of your workforce and the asset itself.
Bear in mind that entropy and maintenance are related. Maintenance is a form of energy (i.e.: effort and spending) that serves to reduce or limit entropy growth and hence chaos in our physical assets. We must do the right maintenance and only that. If we do too much of the wrong maintenance, then we can actually speed up entropy growth. Our energy is being expended to create chaos! Not a good situation, but surprisingly common.
For example, you’ve probably noticed that after plant shutdowns your operators struggle a bit to get the plant running again. It’s common to see failures during startup. This can be caused by two things – the natural disruption of a system that is operating normally by shutting it down can initiate some failure mechanisms. The other cause comes from mistakes. When we maintain the equipment we are very prone to making errors – wrong parts, substandard parts, incorrect assembly, leaving parts out, leaving things loose, etc. Those will lead to failure rapidly after startup. Those mistakes are another form of entropy (it is nasty stuff) and it leads to more entropy (premature failures. One way to avoid this is to keep things running (i.e.: don’t shut down) and if you must shut down, to minimize the amount of intrusive work you do.
Proactive maintenance programs designed “traditionally” rely heavily on “preventive” maintenance and overhauls. Manufacturers’ manuals are full of overhaul and part replacement recommendations. They are also wrong much of the time. That’s a lesson that was learned in the aircraft industry in the 1970s through an exhaustive study of failures that had led to crashes. They revamped their maintenance programs (which made a huge improvement in aircraft safety) and developed a method that could be repeated in any system. That method produces a maintenance program that is tailored exactly to the design and operating capabilities. It is known as “Reliability Centered Maintenance”.
RCM can be used in any facility or operating environment and will produce a properly tailored maintenance program (and a few other desirable outputs as well). It was originally intended to be used at the design stage for new aircraft and can be used at the design of anything. I’ve used it on ships, chemical plants, and complex electronic avionic systems – all at the design stage. It can also be used on existing systems. Again, I’ve used it in all sorts of industrial environments with great success.
There’s no need to get into RCM details here. It simply works. It is highly appropriate where you have critical systems – those production or service delivery systems that you will rely upon for steady revenues. It is also appropriate for systems where safety or the environment might be at risk if you suffer failures. RCM does come at a cost – roughly 2-3% of the capital cost of a new project. Of course, you’d rather spend less, so we limit it to critical systems. However, you will still have a need to tailor maintenance even for the non-critical systems.
Elsewhere, where the consequences of failure how up as repair costs and maybe some minor production/output losses, then RCM is usually overkill. Fortunately, there are other methods that are less rigorous that will also help in tailoring maintenance for those less critical applications. They are ill-suited to critical systems – using them on critical systems is risky and saves little of the analysis cost. But they work well enough where the stakes are lower.
Without getting into technical details, suffice to say that there are methods we can employ at design or even during the operational phase of the asset’s life cycle to tailor the maintenance program to the physical asset and its very specific needs. Spending that little bit of money (energy) on those analyses, will result in a program that if executed properly (another spend of energy) will deliver a reliable, long-lasting stable operation (minimal entropy).
Leave a Reply