Fixing Early Life Failures Can Make Your MTBF Worse
 Let’s say we 6 months of life data on 100 units. We’re charged with looking at the data and determine the impact of fixing the problems that caused the earliest failures.
Let’s say we 6 months of life data on 100 units. We’re charged with looking at the data and determine the impact of fixing the problems that caused the earliest failures.
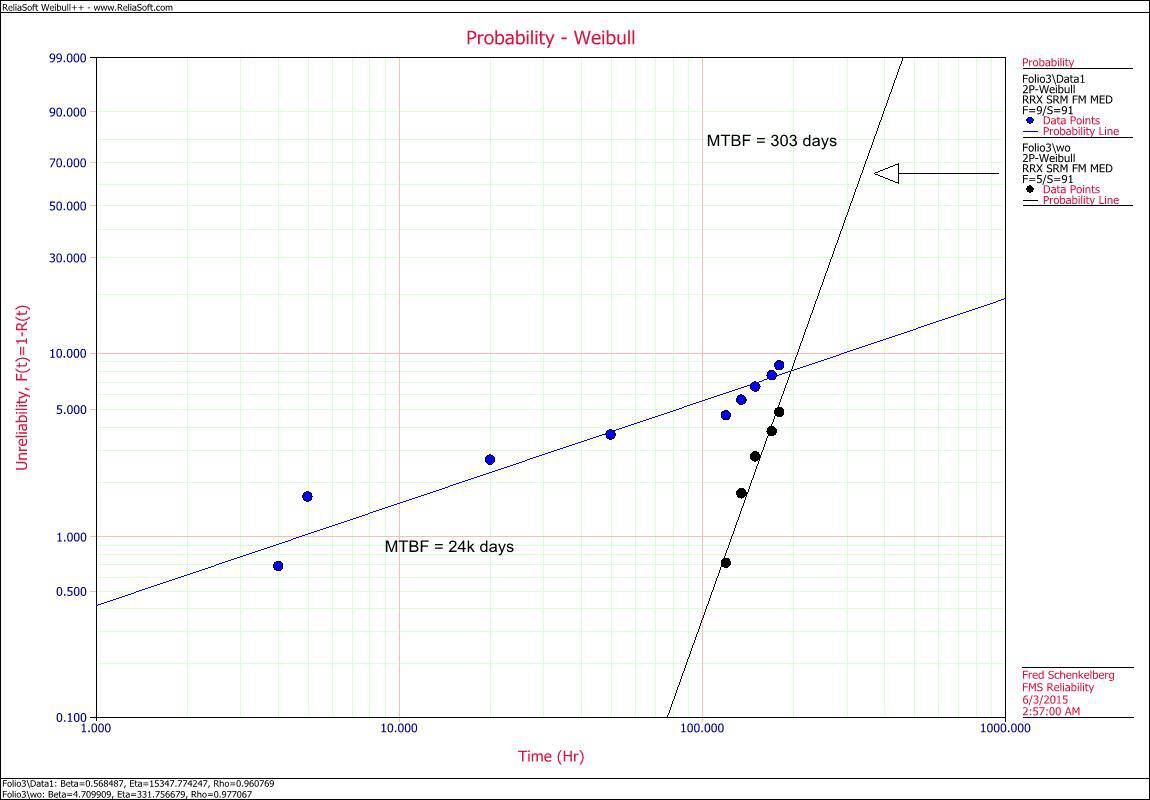
The initial look of the data includes 9 failures and 91 suspensions. Other then the nine all units operated for 180 days. The MTBF is about 24k days. Having heard about Weibull plotting and using the beta value as a guide initially find the blue line in the plot. The beta value is less than one so we start looking for supply chain, manufacturing or installation caused failures, as we suspect early life failures dominant the time to failure pattern.
Initial Steps to Improve the Product
Given clues and evidence that some of the products failed early we investigate and find evidence of damage to units during installation. In fact it appears the first four failures were due to installation damage. The fix will cost some money, so the director of engineer asks for an estimate of the effect of the change on the reliability of the system.
The organization uses MTBF as does the customer. The existing MTBF of 24k days exceeds the customers requirement of 10K days, yet avoiding early problems may be worth the customer good will. The motivation is driven by continuous improvement and not out of necessity or customer complaints.
Calculation of Impact of Change on Reliability
One way to estimate the effect of a removal of a failure mechanism is to examine the data without counting the removed failure mechanism. So, if the change to the installation practice in the best case completely prevents the initial four failures observed we are left with just the 5 other failures that occurred over the 6 months.
Removing the four initial failures and calculating MTBF we estimate MTBF will change to about 300 days.
Hum?
We removed failures and the MTBF got worse?
What Could Cause this Kind of Change?
The classic calculation for MTBF is the total time divided by the number of failures. Taking a closer look at time to failure behavior of the two different failure mechanisms may reveal what is happening. The early failures have a decreasing failure rate (Weibull beta parameter less than 1) over the first two months of operation. Later, in the last couple of months of operation, 5 failures occur and they appear to have an increasing rate of failure (Weibull beta parameter greater than 1).
By removing the four early failures the Weibull distribution fit changes from the blue line to the black line (steeper slope).
Recall that the MTBF value represents the point in time when about 63% of units have failed. With only 9 total failures out of 100 units we have only about 10% of units failed so the MTBF calculation is a projects to the future when most of have failed, it does not providing information about failures at 6 months or less directly.
In this case when the four early failures are removed the slope changed from about 0.7 to about 5, it rotated counter clockwise on the CDF plot.
If only using MTBF the results of removing four failures from the data made the measured MTBF much worse and would have prevented us from improving the product. By fitting the data to a Weibull distribution we learned to investigate early life failures, plus once that failure mechanism was removed revealed a potentially serious wear out failure mechanism.
This is an artificial example, of course, yet it illustrates the degree which an organization is blind to what is actually occurring by using only MTBF. Treat the data well and use multiple methods to understand the time to failure pattern.
This is a great example. If there are competing failure modes, they are there all along, and they’d show up as wear-out failures. Incorrect analysis doesn’t change that.
If reliability engineering were just a matter of analysis, then it would be simple to make a few spreadsheet templates and not work very hard. As you point out with this exercise, understanding the cause of each failure is vital to forming a good analysis.
It is, of course, a good idea to use designs that minimize the potential for installation damage. It is equally important to understand if there are end-of-life issues with one or more components.
Fred,
There is so much to be learned from this post, it is hard to sum it all up. But here are a few tidbits.
To start, it is rather obvious that there ended up being multiple failure modes in this data. (The Weibull plot of the 9 failures did not show a bent regression line though, that there were multiple failures was determined in this example by some engineering discoveries in installation that actually were pure serendipity.) That pretty much eliminates the Weibull model (a unimodal model) from consideration to analyze the entire set of failures.
Second, what would your MTBF’s have been in each case had you included the suspensions (using Benard’s approximation) in the graphs? That is a lot of important data that was ignored. The suspensions might have dominated and the differences in MTBF not been quite so stark.
Third, with graphical inferential methods, you obtain point estimates of the parameters of the model, mean estimates assuming that they are Gaussian distributed (they aren’t, ever, but that is beside the point). An MTBF computed from any point estimates of Weibull parameters can be at any quantile, and it most definitely will not be a mean estimate of MTBF. We in fact have no earthly idea what kind of estimate that MTBF calculation might be doing this. There might be based on this data a 99% probability that the true MTBF is less than these values, we have no way to know.
Fourth, with a Weibull model, the scale parameter (typically eta) is the critical life at which 63.2% of failures will have occurred, not MTBF. The % of failures that will occur by MTBF can range from 0% up to about 72% (if I recall this correctly) with a Weibull model.
The approach you used in your article was a great one, but only because I would bet big that you have actually seen it used in practice many times. But there are so many pathologies in whole process that any decision making is a total crapshoot. The issues with using MTBF are essentially moot.
Send me your data (along with a required reliability number at some life) and I will run my multiple failure mode codes to see if the two failure modes really exist, then run the single failure mode code so we can compare reliability distributions with and without the four early failures, and I will post those results for your example to see if any good decisions can be made at all. I will also provide distributions on MTBF for each case, to show how useless they are as well.
Mark Powell
Hi Mark and all,
here’s the data it is a fictionalized (is that a word?) and read it as one unit failed at day 4, one failed at day 5, and so on. With 100 total units in service for 100 days, thus 91 suspensions at day 180.
1 F 4
1 F 5
1 F 20
1 F 50 – up to here we know the failures are due to installation damage, after this we do not know the cause as of yet.
1 F 120
1 F 135
1 F 150
1 F 170
1 F 180
91 S 180 – 91 are still running at 180 days
The MTBF values are from the Weibull distribution means – the gamma function formula to determine mean given the two parameters of the fitted distribution.
It is not the same as assuming an exponential distribution which doesn’t lead to this shift to lower MTBF value.
For the serious student, what happens over a year (365 days) how many more failures should we expect? and why?
Have fun.
Fred,
I did remember incorrectly after all. Turns out, for a single mode Weibull, for a given value of the scale parameter (eta), MTBF can be at any quantile from about 43% out to 100%. Cannot be smaller than 43%, which is a quirk of the Weibull.
I can’t tell from your plots if the suspensions were included or not. I am trying to remember what Reliasoft does with the suspensions on the plot, whether they are visible or not.
I will run the data and post what I got. Might be interesting.
Mark Powell
Hi Mark,
Have fun, if you have trouble plotting in the comment section I can create a new post to add it to the site.
Cheers,
Fred
Your fictional example ends with suspensions at 180 days. I just wanted to include a reminder that in reality it is possible to have a delay before the onset of some failure mechanisms. In this fictional example, suppose you have some mechanism that takes 250 days before onset then causes almost all samples to fail before 400 days! Well, that’s just a reminder to try to include some acceleration into testing (or be aware of the lack of it). Events like that can also mess up your calculations.
Hi Andrew,
You are right, it is very common that field failure data is very complex.
Cheers,
Fred
Andrew,
Excellent, excellent post!
Suppose that the dreaded old age failure mode that causes 99% of the items to fail by 400 days actually exists in this product? Fred’s director of engineering does not know this, but he does know that they did not do any ALT.
Now the customer, suppose they were in a Mil-STD-217 mindset, is expecting no more than 63.2% of the items to fail by 10k days (exponential model, P(tf<=MTBF)=63.2%). Fred’s director of engineering might lose his job at day 401 (if he cannot pin it on the RE), concern for which is probably why he asked for the differential analysis on MTBF after fixing the installation issue.
Well, what can he do? For one, he could order up the ALT (probably needs HALT by now) that he should have had done in the first place, which should uncover the old age failure mode, and then let him get it fixed. But how is he going to justify this new expense to his bosses? I cannot think of an argument that I would want to present were I in his shoes.
There is another alternative though. Fred’s director of engineering could hire a smart consultant to do a Value of Information analysis for all those potential failure modes that remain undiscovered, and produce cost savings distributions for doing the ALT and fixing those problems earlier. If the probability of saving enough money is high enough, he can certainly take that to his bosses and probably get funded to do the ALT. If it turns out it was too low, then he can take that to his bosses when the old age failure mode catches up with him to convince the bosses to not fire him.
Fred’s director of engineering is at this point at 180 days and he has some decisions to make. We never should forget that all these analyses and tests are done to enable good decision making. And there are a lot of things that can be done in RE that generally aren’t, things that can justify a particular path or save a ton of money.
Mark Powell
Fred,
This is such a great example!
It highlights the types of practices that advanced RE’s might actually use.
First, it does look like you used the suspensions data. I cannot tell with Reliasoft’s plots always. Plus, is there an option on Reliasoft for enabling the “bent” regression line? Looking at your plot it sure should have been there.
Second, unless you do some PoF analysis and determine that 99.99999% of the failures due to the installation problem would occur before say 100 days (before the other failures > 100 days), you have no idea whether the other five data are actually from a different failure mode or not. Also, you will have no idea if any of the suspensions have the installation problem but just did not fail. You really have to be very careful segregating data, especially when you have suspensions, or else you can get total garbage as results.
Now suppose that you did the PoF analysis and the installation problem always would manifest as a failure before 100 days. Then you could segregate the data into the four early failures with no suspensions, and the remaining five data with the suspensions.
I processed these data segregations using the techniques I describe in the “What’s the Fuss about Bayesian Reliability Analysis” article here on noMTBF.com.
For the four early failures, no suspensions:
P(MTBF>10k days) = 0.66%
P(beta 4.4e-3%) = 50%
For the other five failures and the suspensions:
P(MTBF>10k days) = 0%
P(beta 38.52%) = 50%
When I processed all the data together, I still only got P(MTBF>10k days) = 36.281%.
Your Director of Engineering was in big trouble even before discovering the installation failure mode.
I will post more on my multiple failure mode runs soon. Interesting results.
Mark Powell
Fred,
For some reason, WordPress messed up my text on my results. Here goes again.
For the four early failures, no suspensions:
P(MTBF>10k days) = 0.66%
Probability of infant mortality failure mode: 69.395%
Probability that Reliability at 365 days exceeds 4.4e-3%: 50%
For the other five failures and the suspensions:
P(MTBF>10k days) = 0%
Probability of infant mortality failure mode: 0%
P(MTBF>303 days) = 62.45%
Probability that Reliability at 365 days exceeds 38.52%: 50%
When I processed all the data together, the Probability of MTBF > 24k days was only 16.91%. Your director of engineering was really mislead by those results from the MRR Weibull parameter estimates.
The lesson here should be obvious: you can never trust any value computed from MRR estimates of Weibull parameters to make any decision (actually, you cannot trust any value computed from any point estimates of anything).
Let’s see how this post looks.
Mark Powell
Fred,
Ran my codes for multiple failure modes on the entire data set. Interesting results.
First, the Markov chain stabilized, so there were two failure modes detected. The mixture parameter was not sharp, which I attribute to there being an order of magnitude more suspensions than failures. However, as a curiousity, the mean mixture ratio was 44%, almost exactly the ratio of the two failure modes in the data.
The probability of one failure mode being infant mortality was 87.6%, and for the other 0%.
The probability of MTBF >24000 days was only 3.32%, which really says that processing multiple failure modes using MRR for a single failure mode is a really bad idea (you got 24k days for MTBF).
The probability of MTBF>10000 days (customer’s requirement) was just 13.79%.
If the customer was thinking Mil-STD-217, then they expected reliability at 10,000 days to exceed 36.8%. The probability of the reliability at 10,000 days exceeding 36.8% was just 2.1%. Not good.
This example of yours really illustrates a whole slew of things that you should never do.
Mark Powell
Hi Mark, thanks for the analysis and the link to your previous work detailing how the analysis is done. I for one need to review that work and see if I can replicate your results. cheers, Fred
PS: would you be willing to create a posting that steps through the analysis you have done above?
Fred,
Basically, I merely repeated the single failure mode analyses using the first paper I have posted on my website (http://www.attwaterconsulting.com/Papers.htm), and the multiple failure mode analysis using the seventh paper. Those papers derive everything from scratch, and the results in both have been reproduced more times than I can count. Once I got the samples for all the parameters in each run, it is merely a matter of plugging them into the familiar Weibull equations to get samples of whatever you might want to compute (like MTBF or a reliability – all outlined in that transformation bit in the “What’s the Fuss” article as well). Then it is a snap to compute the probabilities I provided.
I used the same codes as used in those papers, and the only tricky part is the art of getting the Markov chains to stabilize. Once they do though, regardless of where they start, the results agree to within the fundamental numerical method error for MC. I used 100,000 samples, so they ought to be good to within a percent.
This example of yours really is a good one for a lot of things you should absolutely not do, and why, and I will bet you have actually seen something like that done in real life.
Mark Powell
Fred,
I neglected to mention that I was surprised that my multiple-failure-mode code worked so well with only nine failures. I have never run it with so few event data, and was concerned that the Markov chains would not stabilize because of so minimal information content, but they did rather nicely.
This method may be a lot more powerful than I even thought.
Also, for steps on how I did these analyses, I used the exact same steps as in the “What’s the Fuss” article. That might be clearer than trying to follow some academic style paper.
Mark Powell