
Basic Reliability Definition
Occasionally, I like to step back and reflect on reliability in basic terms.
In that spirit, the basic premise of reliability is usually stated as “The probability that an item will perform a required function, without failure, under stated conditions, for a stated period of time.”
To use the reliability equation, the definition of failure must be defined, so you can tell if your equipment has indeed failed. This way you can include it in the MTBF (Mean Time Between Failure) calculation.
After you have defined a failure and recorded them appropriately, you can plug the numbers into the reliability equation, R = e ^-(λ*t) where λ is the failure rate which is defined as λ= 1/MTBF and come up with an objective value for the reliability.
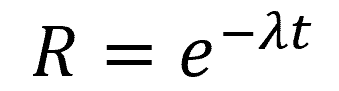 Based on this equation, as the number of failures goes down, the reliability increases assuming all the other parameters stay unchanged.
Based on this equation, as the number of failures goes down, the reliability increases assuming all the other parameters stay unchanged.
This is important because I can also increase the reliability by reducing the “t”, or mission time the system is expected to perform the function.
In other words, if I can’t make a system go 8 hours without a failure, I would have R = 0. However, if it could always be counted on to go 7 hours without a failure, then I could change the mission time to 7 hours and have R = 1 (100% probability of going 7 hours without a failure).
In a manufacturing environment, they are always looking to extend the mission time so we tend to ignore the time adjustment issue. As company’s try to achieve improved reliability, they implement systems, hire consultants, install software, establish preventive maintenance programs, implement RCM, and many other great tools which all are all necessary to provide or support maintenance strategies to increase reliability.
Which is just another way of saying eliminate or reduce failures.
It is all about eliminating failures

So at a basic level, it is all about eliminating or reducing failures.
For example, one of my first forays into reliability was an issue with a bearing that was causing significant downtime. There were four identical systems, and the plant had floated a capital improvement authorization to add a 5th.
The reason for this was they couldn’t keep the system running due to bearing failures. I started investigating, and a tradesperson suggested that we should look at system one. “Why?”, I asked. “Because system one isn’t failing,” they replied.
I then wanted to know why system one was not failing The tradesperson didn’t know, so we scheduled an inspection to see if we could find out.
As the mechanic started to raise the pillow block cover, I said: “Ok you can put it back down.” The tradesmen looked at me like I was crazy. I asked him to do it again, but this time I asked him to look at the bearing.
He did and realized the same thing – it was different than all the others.
So, we buttoned it up and investigated. Luckily the system we just inspected had not had a bearing changed in a while and that drove us to uncover the fact that someone had replaced the spherical ball bearing with a spherical roller bearing.
Others had just continued to follow suit and the problem perpetuated itself.
Continuous improvement
So, we put the correct bearing in all of the four systems, canceled the capital improvement authorization, and I got an honorable mention from the plant manager.
We could have stopped there, but I kept asking “why?” when one of the bearings failed. That led us to other issues.
We had to correct things such as improper installation; incorrect internal clearances; not correcting for soft foot, using poor alignment practices (time card and eyeball), not correcting for hot alignment, incorrect use of lubricant and incorrect frequency of lubrication, and no vibration monitoring.
Most will recognize that doing all of these things is now what is referred to as precision installation.
The reliability of this system was improved by simply extending the MTBF from 1 month to 8 years, and we saved significant maintenance dollars and time.
We improved the reliability so much that shortly before I left the plant, I got a call from the maintenance crew supervisor saying that they were having problems with the same systems.
In doing the root cause, it turns out that they were so reliable that people had forgotten how to fix them.
At the time, we had no CMMS, no PM program, obviously training issues, and had never heard of RCM.
I was also using an oscilloscope-type of analyzer to do vibration analysis with an X/Y pen plotter to capture the signature. From this experience, I learned that improving MTBF through Root Cause Analysis or defect elimination first, it can be quick and cost effective and it also doesn’t hurt your career.
I learned that it provided the quick wins that management wanted and that allowed them to take the leap of faith (for them) to support reliability. I also learned that after doing Root Cause Analysis, there was still a need to capture the lessons learned in the CMMS.
This became evident after eight years and the lessons hadn’t been captured in order to be passed on to others.
It showed that there was a proper timing to implementation to each of the tools that are available.
Lessons learned
So what has changed from that time which was back in the mid-1980’s?
We have better vibration equipment and RCM. We have FMEA’s and state of the art CMMS, to name just a few. These are all valuable tools and integrate into an overall reliability program. The simple bearing example used in this article always makes me careful when discussing how to best attack an improvement project.
I can use all the tools available today, have no unscheduled downtime on equipment but still be doing more maintenance than necessary.
My lesson learned from this plant experience was that basic root cause analysis has a very prominent place in the total reduction of overall costs.
Many times it should be the first thing considered to implement in your program because as the title of this article suggests, it provides the bedrock on which to build your program.
Please let me know if you think RCA is the bedrock – if you don’t agree, what is?
 Ask a question or send along a comment.
Please login to view and use the contact form.
Ask a question or send along a comment.
Please login to view and use the contact form.
Leave a Reply